Disk is OK
Maybe I am unlucky with computer hardware.
Maybe I have the opposite of the golden touch of Midas.
Or maybe it’s just the fact that I use my hardware for things they were never meant to be used for.
Anyway, I have acquired two Seagate 4TB external hard drives for doing some testing with ZFS. I shucked them (took them out of their enclosure) and started using them as internal drives in many different configurations.
Funnily enough, even though the two external drives had different branding (Backup Plus, Expansion) and enclosure design, the hard drives in them were identical.
Some info about the drives:
- Model: ST4000LM024-2AN17V
- Recording type: SMR (shingled magnetic recording)
- Form factor: 2.5"
- Interface: SATA
- Thickness: 15 mm
Before I get to the stupid stuff, I would like to mention what these drives are good for, and where they suffer heavily.
Good:
- WORM (write once, read many) type of workloads, such as a Steam library, your media collection etc.
Bad:
- random read/write workloads (performance is absolutely rubbish and makes the system unusable)
- write heavy workloads (SMR requires some clean-up activities that are managed by the drive, and you cannot do anything while those take place)
The stupid stuff
I have done some pretty dumb things with these, such as using them in an InWin Chopin computer case and letting them hit 60C under load. Fun fact: these drives actually fit almost perfectly in the case, as long as you bend one small metal section for one of the drive cages. Not so fun fact: they will overheat if you have a high CPU load and you cannot do much about that.
Currently these drives are sitting in my main desktop. Initially I tried using them in a mirrored configuration under Windows, because having your whole Steam library downloaded with disk space to spare is pretty cool. Unfortunately, one of the disks started having issues and it got kicked out of the mirror. It kept doing this every time it accumulated bad sectors.
Now these two sit in a ZFS mirror configuration inside a VM, acting as some sort of a temporary scratch disk. Another
free fun fact: kvm (or qemu, or libvirt, one of those) will pause the VM if it detects that one of your disks has
encountered I/O errors, and seems that the only “fix” is to force a restart of the VM (could not unpause the VM).
It has become some sort of a fun pastime for me to keep an eye on one of the failing drives and the status of the ZFS mirror.
Will ZFS detect some errors?
How large can the bad sector count get before the drive dies?
When will it actually die?
Why is S.M.A.R.T still reporting that the disk is OK?
So far, so good.
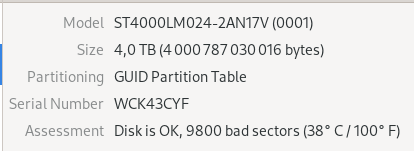
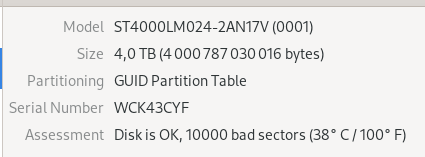

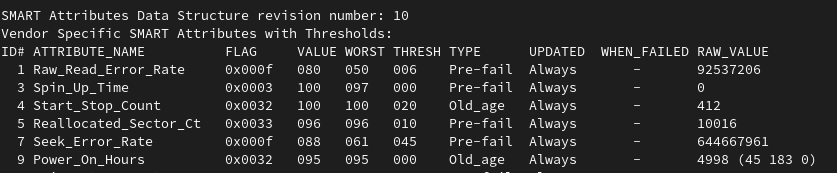
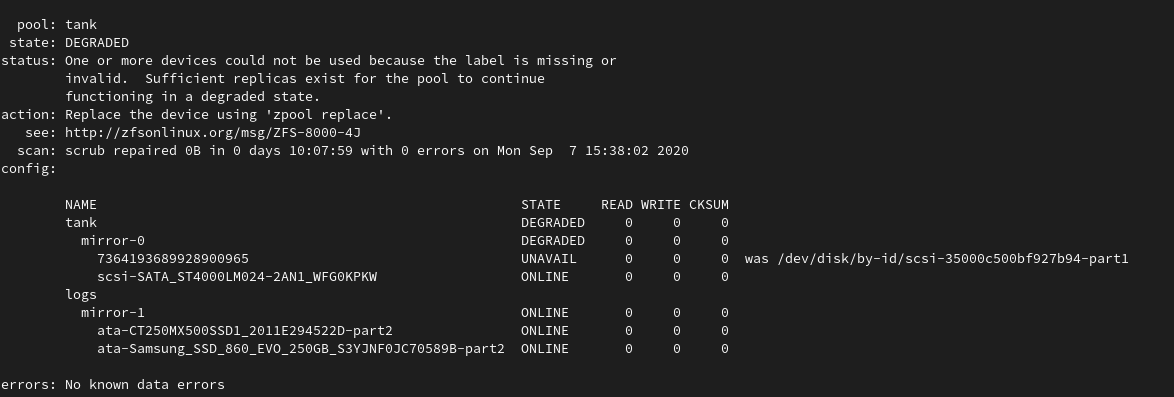
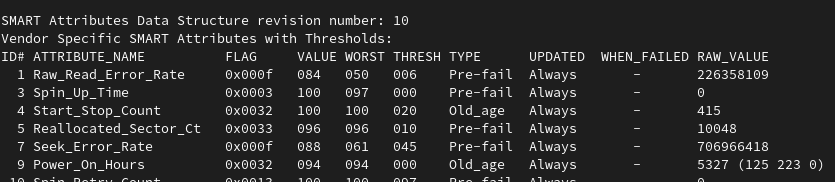
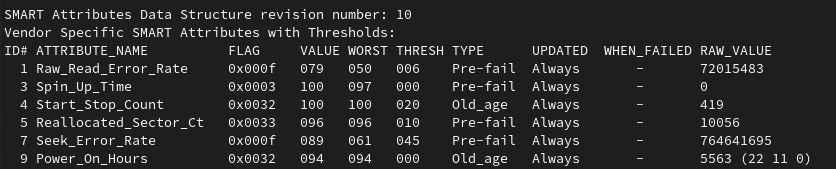
Expect this list to grow with time.
Subscribe to new posts via the RSS feed.
Not sure what RSS is, or how to get started? Check this guide!
You can reach me via e-mail or LinkedIn.
If you liked this post, consider sharing it!