Why my blog was down for over 24 hours in November 2024
In November 2024, my blog was down for over 24 hours.
Here’s what I learned from this absolute clusterfuck of an incident.
Lead-up to the incident
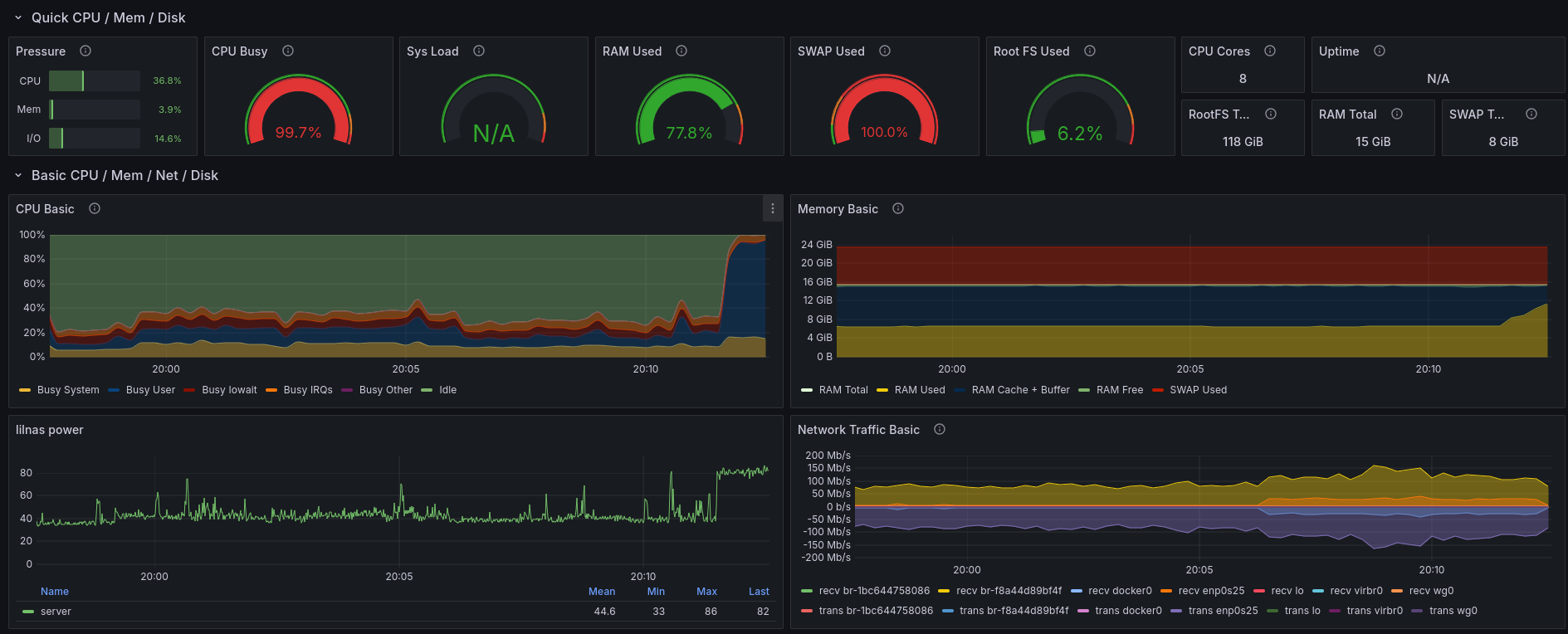
I was browsing through photos on my Nextcloud instance. Everything was fine, until Nextcloud started generating preview images for older photos. This process is quite resource intensive, but generally manageable. However, this time the images were high quality photos in the 10-20 MB size range.
Nextcloud crunched through those, but ended up spawning so many processes that it ended up using all the available memory on my home server.
And thus, the server was down.
This could have been solved by a forced reboot. Things were complicated by the simple fact that I was 120 kilometers away from my server, and I had no IPMI-like device set up.
So I waited.
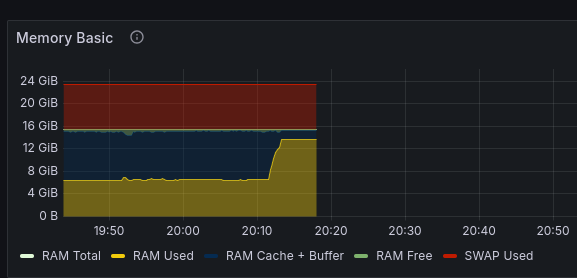
50 minutes later, I successfully logged in to my server over SSH again! The load averages were in the three-digit realm, but the system was mostly operational.
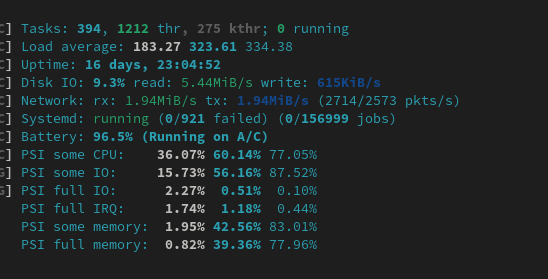
I thought that it would be a good idea to restart the server, since who knows what might’ve gone wrong while the server was handling the out-of-memory situation.
I reboot.
The server doesn’t seem to come back up. Fuck.
The downtime
The worst part of the downtime was that I was simply unable to immediately fix it due to being 120 kilometers away from the server.
My VPN connection back home was also hosted right there on the server, using this Docker image.
I eventually got around to fixing this issue the next day when I could finally get hands-on with the server, my trusty ThinkPad T430. I open the lid and am greeted with the console login screen. This means that the machine did boot.
I log in to the server over SSH and quickly open htop. My htop configuration shows metrics like systemd state, and
it was showing 20+ failed services. This is very unusual.
lsblk and mount show that the storage is there. What was the issue?
Well, apparently the Docker daemon was not starting. I was searching for the error messages and ended up on this GitHub issue. I tried the fix, which involved deleting the Docker folder with all the containers and configuration, and restarted the daemon and containers. Everything is operational once again.
I then rebooted the server.
Everything is down again, with the same issue.
And thus began a 8+ hours long troubleshooting session that ran late into the night. 04:00-ish late, on a Monday.
I tried everything that I could come up with:
- used the
btrfsDocker storage driver instead of the default overlay one- Docker is still broken after a reboot
- replaced everything with
podman- I could not get
podmanto play well with my containers and IPv6 networking
- I could not get
- considered switching careers
- tractors are surprisingly expensive!
I’m unable to put into words how frustrating this troubleshooting session was. The sleep deprivation, the lack of helpful information, the failed attempts at finding solutions. I’m usually quite calm and very rarely feel anger, but during these hours I felt enraged.
The root cause
The root cause will make more sense after you understand the storage setup I had at the time.
The storage on my server consisted of four 4 TB SSD-s, two were mounted inside the laptop, and the remaining two were
connected via USB-SATA adapters. The filesystem in use was btrfs, both on the OS drive and the 4x 4TB storage pool. To
avoid
hitting the OS boot drive with unnecessary writes, I moved the Docker data root to a separate btrfs subvolume on the
main storage pool.
What was the issue?
Apparently the Docker daemon on Fedora Server is able to start up before every filesystem was mounted. In this case, Docker daemon started up before the subvolume containing all the Docker images, containers and networks was mounted.
I tested out this theory by moving the Docker storage back to /var/lib/docker, which lives on the root filesystem, and
after a reboot everything remained functional.
In the past, I ran a similar setup, but with the Docker storage on the SATA SSD-s that are mounted inside the laptop over a native SATA connection. With the addition of two USB-connected SSD-s, the mounting process took longer for the whole pool, which resulted in a race condition between the Docker daemon startup and the storage being mounted.
Fixing the root cause
The fix for Docker starting up before all of your storage is mounted is actually quite elegant.
The Docker service definition is contained in /etc/systemd/system/docker.service. You can override this configuration
by creating a new directory at /etc/systemd/system/docker.service.d and dropping a file with the name override.conf
in there with the following contents:
[Unit]
RequiresMountsFor=/containerstorage
The rest of the service definition remains the same and your customized configuration won’t be overwritten with a Docker
version update. The RequiresMountsFor setting prevents the Docker service from starting up before that particular
mount exists.
You can specify multiple mount points on the same line, separated by spaces.
[Unit]
RequiresMountsFor=/containerstorage /otherstorage /some/other/mountpoint
You can also specify the mount points over multiple lines if you prefer.
[Unit]
RequiresMountsFor=/containerstorage
RequiresMountsFor=/otherstorage
RequiresMountsFor=/some/other/mountpoint
If you’re using systemd unit files for controlling containers, then you can use the same systemd setting to prevent
your containers from starting up before the storage that the container depends on is mounted.
Avoiding the out of memory incident
Nextcloud taking down my home server for 50 minutes was not the root cause, it only highlighted an issue that had been there for days at that point. That doesn’t mean that this area can’t be improved.
After this incident, every Docker Compose file that I use includes resource limits on all containers.
When defining the limits, I started with very conservative limits based on the average resource usage as observed from
docker stats output.
Over the past few months I’ve had to continuously tweak the limits, especially the memory ones, due to the containers themselves running out of memory when the limits were set too low. Apparently software is getting increasingly more resource hungry.
An example Docker Compose file with resource limits looks like this:
name: nextcloud
services:
nextcloud:
container_name: nextcloud
volumes:
- /path/to/nextcloud/stuff:/data
deploy:
resources:
limits:
cpus: "4"
memory: 2gb
image: docker.io/nextcloud:latest
restart: always
nextcloud-db:
container_name: nextcloud-db
volumes:
- /path/to/database:/var/lib/postgresql/data
deploy:
resources:
limits:
cpus: "4"
memory: 2gb
image: docker.io/postgres:16
restart: always
In this example, each container is able to use up to 4 CPU cores and a maximum of 2 GB of memory. And just like that, Nextcloud is unable to take down my server by eating up all the available memory.
Yes, I’m aware of the Preview Generator Nextcloud app. I have it, but over multiple years of running Nextcloud, I have not found it to be very effective against the resource-hungry preview image generation happening during user interactions.
Decoupling my VPN solution from Docker
With this incident, it was also clear that running your gateway to your home network inside a container was a really stupid idea.
I’ve mitigated this issue by taking the WireGuard configuration generated by the container and moving it to the host. I also used this as an opportunity to get a to-do list item done and used this guide to add IPv6 support inside the virtual WireGuard network. I can now access IPv6 networks everywhere I go!
I briefly considered setting WireGuard up on my openWRT-powered router, but I decided against it as I’d like to own one computer that I don’t screw up with my configuration changes.
Closing thoughts
I have not yet faced an incident this severe, even at work. The impact wasn’t that big, I guess a hundred people were not able to read my blog, but the stress levels were off the charts for me during the troubleshooting process.
I’ve long advocated for self-hosting and running basic and boring solutions, with the main benefits being ease of maintenance, troubleshooting and low cost. This incident is a good reminder that even the most basic setups can have complicated issues associated with them.
At least I got it fixed and learned about a new systemd unit setting, which is nice.
Still better than handling Kubernetes issues.
Subscribe to new posts via the RSS feed.
Not sure what RSS is, or how to get started? Check this guide!
You can reach me via e-mail or LinkedIn.
If you liked this post, consider sharing it!